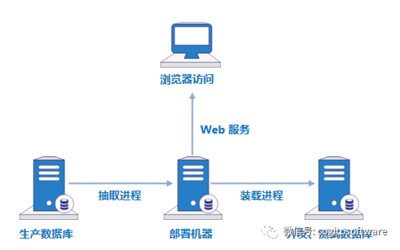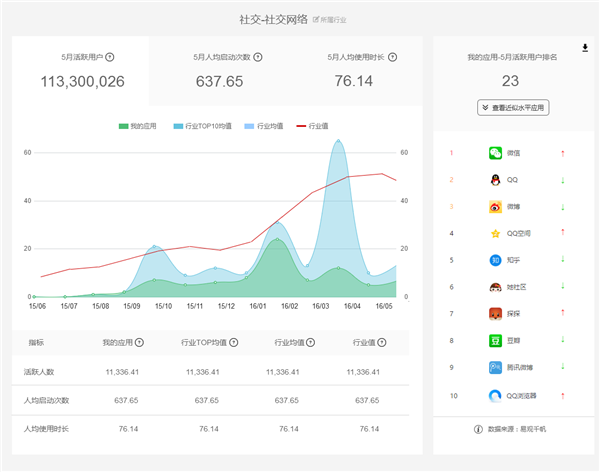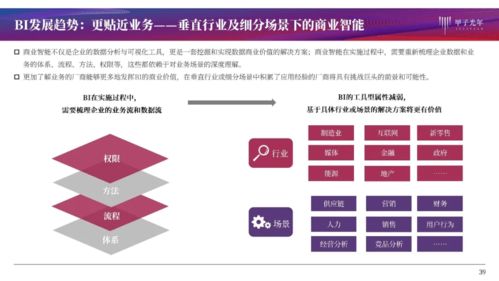
在數(shù)據(jù)驅動的時代,數(shù)據(jù)分析工具的選擇對工作效率和決策質量至關重要。面對市場上琳瑯滿目的工具,如何做出明智的選擇?關鍵在于從數(shù)據(jù)處理的核心需求出發(fā),綜合考慮多個維度。以下是選擇合適數(shù)據(jù)分析工具的實用指南。
一、明確數(shù)據(jù)分析的目標與規(guī)模
清晰定義分析目標。是進行探索性數(shù)據(jù)分析(EDA)、制作可視化報表、構建預測模型,還是執(zhí)行復雜的數(shù)據(jù)挖掘?不同目標對應不同的工具:
- 探索性分析:適合使用Python(Pandas、Jupyter)或R,它們靈活且擁有豐富的統(tǒng)計庫。
- 商業(yè)智能(BI)報表:Tableau、Power BI或FineBI等可視化工具更高效。
- 大規(guī)模數(shù)據(jù)處理:需考慮Hadoop、Spark等分布式框架。
評估數(shù)據(jù)規(guī)模。小數(shù)據(jù)集(如Excel表格)可能用Excel或簡單腳本即可;而TB級大數(shù)據(jù)則需要專業(yè)的大數(shù)據(jù)平臺。
二、評估數(shù)據(jù)處理的技術需求
數(shù)據(jù)處理涉及清洗、轉換、整合等環(huán)節(jié),工具需滿足技術要求:
- 數(shù)據(jù)清洗能力:檢查工具是否支持缺失值處理、去重、格式轉換等功能。Python的Pandas和OpenRefine都是強大選擇。
- 數(shù)據(jù)源兼容性:工具應能連接多樣數(shù)據(jù)源,如數(shù)據(jù)庫(MySQL、PostgreSQL)、云服務(AWS、Google Cloud)或API。KNIME和Alteryx在此方面表現(xiàn)突出。
- 處理速度與性能:對于實時數(shù)據(jù)處理,需考慮流處理工具如Apache Kafka或Flink。
三、考慮團隊技能與協(xié)作因素
工具的選擇必須與團隊能力匹配:
- 學習曲線:非技術團隊可能更適合拖拽式工具(如Tableau Prep或Trifacta),而開發(fā)團隊則可駕馭編程型工具。
- 協(xié)作功能:現(xiàn)代數(shù)據(jù)分析常需團隊合作。尋找支持版本控制(如Git集成)、共享儀表板或云端協(xié)作的工具,例如Databricks或Google Data Studio。
四、權衡成本與可擴展性
預算是現(xiàn)實約束:
- 開源工具:如Python、R、Apache Superset,成本低但需自主維護。
- 商業(yè)軟件:如SAS、IBM SPSS,提供專業(yè)支持但費用較高。
考慮長期可擴展性。選擇能夠隨著業(yè)務增長而擴展的工具,避免頻繁遷移數(shù)據(jù)帶來的麻煩。
五、實踐建議與常見陷阱
- 先行試用:大多數(shù)工具提供免費試用版,親身體驗后再決定。
- 避免“一刀切”:不同場景可能需組合使用多種工具,例如用Python處理數(shù)據(jù),再用Tableau可視化。
- 警惕過度復雜化:不要盲目追求功能最全的工具,簡單高效的方案往往更可持續(xù)。
###
選擇數(shù)據(jù)分析工具沒有唯一標準答案,但遵循“需求驅動”原則能大幅降低決策風險。回歸數(shù)據(jù)處理的本源——你究竟想從數(shù)據(jù)中獲得什么?答案將指引你找到最適合的利器。記住,最好的工具是那個能讓數(shù)據(jù)流暢轉化為洞察的伙伴。